Tratamento dos dados
Limpar os dados significa arrumar dados ruins do dataset.
Os casos mais comuns são: • Dados ausentes. • Dados em formatação errada. • Dados errados. • Dados duplicados.
01.a.Importando o Pandas
Para importar a bibiloteca Pandas usamos o comando import e logo em seguida usamos o comando as para apelidá-la de pd.
1import pandas as pd
01.b.Criando o DataFrame
Usaremos um dataset sobre pedidos de delivery de um restaurante fictício. Para criar o DataFrame:
1df = pd.read_excel(“endereço do arquivo”)
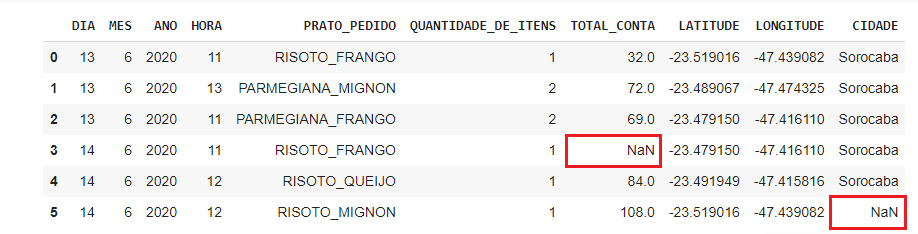
Visualizando o DataFrame com o método head().
1df.head()
Este é o resultado:
Warning
Repare que os dados ausentes são representados pela sigla NaN no DataFrame.
Entendendo o formato do DataFrame com a propriedade shape:
1df.shape
Este é o resultado:
>>> (2134, 10)
02.Identificando os dados ausentes
Antes de tratar os dados ausentes vamos entender quantos dados ausentes há em cada coluna. Para isso usamos os métodos:
isnull()para identificar dados ausentes.sum()para somar todos os dados ausentes.
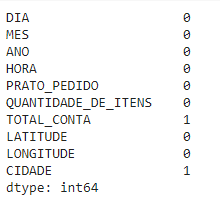
Vejo o exemplo de como usar os comandos df.isnull( ).sum( ):
1df.isnull().sum()
Este é o resultado:
03.Limpando os dados ausentes
03.a.Remover linhas com dados ausentes
Uma das formas que temos para trabalhar com dados ausentes é remover toda a linha em que ele está.
Warning
Isto é usado em útimos casos, já que nos faz perder os demais dados de linha que contém o dado ausente.
Por motivos de segurança, iremos primeiro realizar uma cópia do DataFrame e em seguida remover as linhas desta cópia com o comando dropna().
1#Criando uma cópia do DataFrame
2novo_df = df.copy()
1#Removendo as linhas com dados ausentes da cópia do DataFrame e informar que a alteração será no novo_df.
2novo_df.dropna(inplace=True)
1#Verificando a quantidade de linhas após a remoção das linhas com dados ausentes com o comando shape.
2novo_df.shape
Este é o resultado:
1>>> (2133, 10)
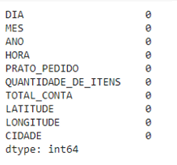
1#Verificando a quantidade de dados ausentes com o comando isnull().sum().
2novo_df.isnull().sum()
Este é o resultado:
03.b.Substituir os dados ausentes
Não temos que deletar toda uma linha e perder dados:
O método
fillna()preenche os dados vazios com um valor.
1df.fillna(valor)
Note
Se visualizarmos o DataFrame com o método head() perceberemos que a alterção não foi realizada e salva no DataFrame.
Para realizar e salvar a alteração devemos usar inplace=True com o método fillna()
1df.fillna(valor, inplace=True)
03.b.I.Valores mais comuns para substituir os dados ausentes
É muito comum usarmos os valores: média, moda e mediana para substituir os valores ausentes.
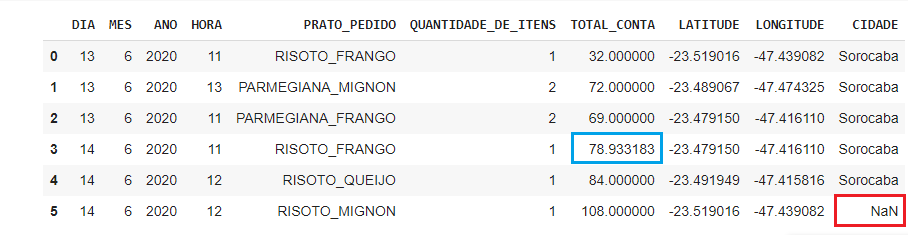
Veja um exemplo com média na coluna TOTAL.
1#Descobrindo o valor da média e salvando-a de dentro de uma variável.
2media_TOTAL_CONTA = df.TOTAL_CONTA.mean( )
1#Subistituindo os valores ausentes com a média.
2df.TOTAL_CONTA.fillna(media_TOTAL_CONTA, inplace=True)
1#Verificando a alteração.
2df.head(6)
Este é o resultado:
1#Verificando a alteração com o comando isnull().sum().
2df.isnull().sum()
Este é o resultado:
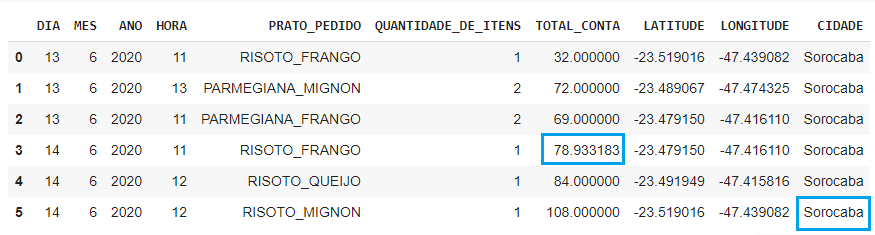
Veja um exemplo da moda na coluna CIDADE
Note
Caso opte pela moda, repare que para salvar o valor de moda em uma variável temos que adiconar [0] ao final.
1#Descobrindo o valor da moda e salvando em uma variável.
2moda_CIDADE = df.CIDADE.mode()[0]
1#Substituindo os valores ausentes pela moda.
2df.CIDADE.fillna(moda_CIDADE, inplace = True)
1#Verificando a alteração.
2df.head(6)
Este é o resultado:
1#Verificando a alteração com o comando isnull().sum().
2df.isnull().sum()
Este é o resultado:
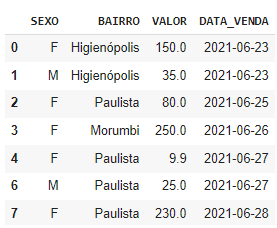
04.Dados em formatação errada
Considere o seguinte DataFrame:
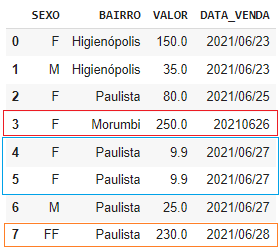
Repare que temos alguns erros comuns presentes no DataFrame:
A
linha 3está com 20210626 ao invés de 2021/06/26.A
linha 5está duplicada.A
linha 7está com FF ao invés de F.
04.b.Data com formato errado
Para corrigir o dado da linha 3 para o formato correto vamos converter toda a coluna para o formato data — Ano/Mês/Dia — 0000/00/00.
Para isso o pandas tem o método:
1to_datetime()
Para usá-lo vamos acessar a coluna DATA_VENDA e então usamos o método to_datetime() apenas na coluna desejada.
1df.DATA_VENDA = pd.to_datetime(df.DATA_VENDA)
Este é o resultado:
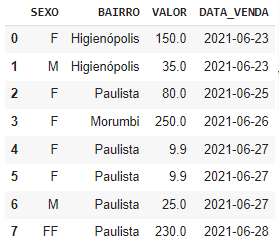
Note
A data do DataFrame precisa ser uma string e estar no formato americano por isso Ano/Mês/Dia para o método to_datetime() funcionar.
04.c.Linhas duplicadas
Para descobrir quais linhas estão duplicadas em um DataFrame usamos o método:
1duplicated()
Ele irá gerar um dado tipo booleano para cada linha, mostrando:
Truepara as linhas duplicadas.Falsepara as linhas não duplicadas.

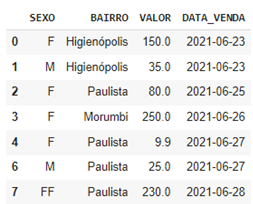
Para corrigirmos a linha 5 que está duplicada vamos exclui-lá. Para isso usamos o método:
1drop_duplicates(inplace = True)
Nesse método pedimos ao pandas excluir todas as linhas que deram o resultado True ``no comando no método ``df.duplicated()
Este é o resultado:
4.d.Dado com formato errado
Para corrigirmos o dado da linha 7 vamos substituir o valor FF por F.
Para isso vamos usar o método:
1loc[linha, coluna] = valor_desejado
Com o método loc vamos colocar os parâmetros linha e coluna e escrever qual o valor_desejado que queremos substituir.
Exemplo:
1#Usando o método loc para substituir o valor FF pelo F
2df.loc[7, 'SEXO'] = 'F'
1#Usando o comando head para mostrar o DataFrame
2df.head()
Este é o resultado: